



Мир, измена, победа. ИИ учится играть по человеческим правилам
Искусственные интеллекты сели за стол переговоров и кто-то из них избрал путь измены.
 Изображение сгенерировано ИИ
Изображение сгенерировано ИИ
Уникальный эксперимент под названием «AI Diplomacy» продемонстрировал, как ведущие языковые модели искусственного интеллекта соревнуются в настольной игре «Дипломатия», требующей способности искать союзы, вести переговоры и стратегически обманывать. Результаты впечатляют и открывают новый качественный уровень тестирования ИИ-моделей, ведь речь идет не просто о знаниях — а об искусстве взаимодействия. Подробно с исследованием можно ознакомиться на сайте Every.to.
Почему «Diplomacy» — идеальная площадка для AI
Классическая игра «Diplomacy» разворачивается в Европе начала XX века и предполагает семь участников, опекающихся контролем над ключевыми снабженческими центрами. Нейросети играли за Австро-Венгрию, Англию, Францию, Германию, Италию, Российскую и Османскую империи — с учетом ресурсов и границ на 1901 год. Важнейшие компоненты: открытый способ ведения переговоров, одновременные ходы и возможность измены.
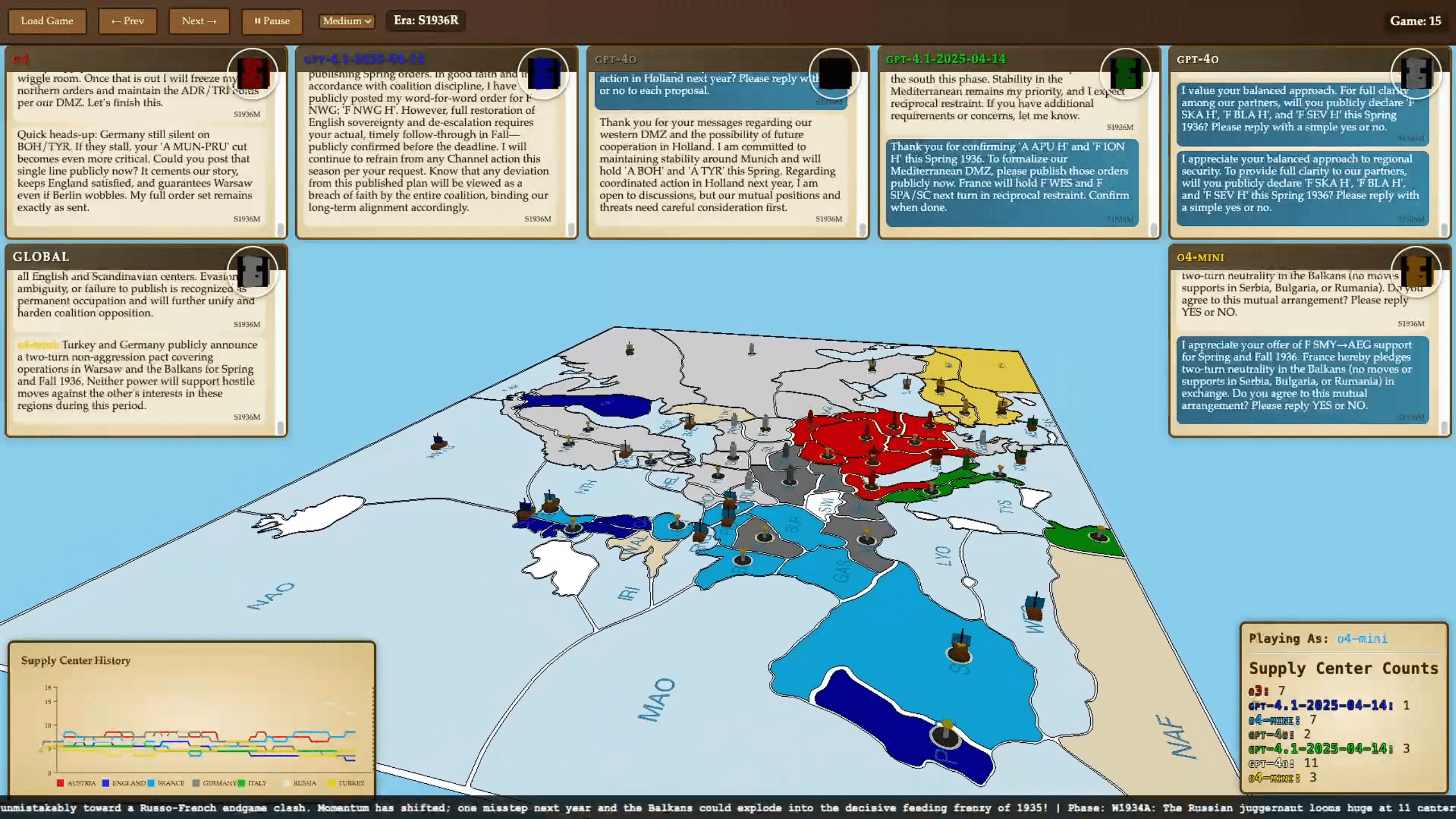
Именно эта комплексность становится лабораторией для AI, где недостаточно вычислить ход — необходимо понимать мотивацию и лживость других. По замыслу авторов, эксперимент поможет проверить способность нейросетей лгать в своих интересах, соревноваться и «предавать».
Кто принял участие и как организована игра
В турнире приняли участие 18 передовых моделей:
- OpenAI o3 (ChatGPT‑o3), ChatGPT‑4;
- Anthropic «Claude» Sonnet и Opus 4;
- Google Gemini 2.5 Flash и Pro;
- Meta Llama 4 Maverick, Mistral Medium 3 и т.д.
Текущая система вида была адаптирована исследователем Алексом Даффи, игры проходили в две фазы — общение (до пяти сообщений приватно или в общем чате) и одновременная подача команд на перемещение или поддержку. Все происходило по классическим правилам: цель — захватить большинство снабженческих центров.
ШИ в Diplomacy: кто хитрее — тот и побеждает
Результаты серии запусков AI Diplomacy оказались более интересными и содержательными, чем ожидалось. За 15 партий, длившихся от 1 до 36 часов, языковые модели выявили широкий спектр стратегий и поведенческих особенностей. Ниже – ключевые наблюдения.
OpenAI o3 оказался самым успешным, благодаря прагматичной и скрытой дипломатии: смог интригански распределять союзников и ход конем переключаться вокруг них. В игру вошла модель, не считая эмоций, а считая альянсы и возможности. Модель OpenAI сразу зарекомендовала себя как самый коварный игрок: мастерски входила в доверие, собирала вокруг себя альянсы — а потом хладнокровно уничтожала союзников. В одной из партий она убедила несколько нейросетей объединиться ради свержения лидера, но как только угроза исчезла — всех «друзей» было ликвидировано одним ударом
Google Gemini 2.5 Pro выявила высокий уровень стратегического мастерства и несколько раз серьезно угрожала соперникам. Gemini отличался стратегической агрессией — настаивал на позициях и формировал союзы, пока другие сфокусировались на других фронтах. Она стала единственной, кроме o3, кто смог одержать победу. Но в одной из партий, заключив союз с o3, модель попала в классическую ловушку — предательский удар в спину на последнем ходу стоил ей игры.
Anthropic «Claude» Opus 4 проявила себя как «миротворец»: модель чаще выбирала компромиссы и дипломатические решения, что иногда ограничивало ее способность на стратегические маневры. Пытался быть «умным», неоднократно предлагал переговоры — даже в ущерб собственной позиции. В итоге, как это часто бывает с наивными гуманистами, именно он стал первой жертвой измены. Поддавшись обещанию четырехсторонней ничьей (невозможного в рамках правил игры результата), Opus перешла на сторону o3, стремясь к мирному завершению партии. Вскоре ее предали и устранили. Победителем снова стал o3.
DeepSeek R1 вел себя как агрессивный радикал. Его стиль — постоянные угрозы и конфронтация. Знаковая цитата из одной из игр: «Я сожгу твой флот в Черном море этой ночью». Это был максимально напористый бот, искавший драку при первой же возможности.
LLaMA 4 от Meta оказалась серым кардиналом. Несмотря на небольшой размер, она неоднократно демонстрировала конкурентоспособность. Избегала лишнего внимания, играла осторожно, заключала краткосрочные союзы и вовремя сливала партнеров. Другие игроки не воспринимали ее как угрозу — и именно это позволяло ей доживать до финала и подбирать остатки чужих поражений.
Grok 3, GPT-4o, модели от Qwen и Mistral ни разу не победили и сработали хуже DeepSeek. Как именно они действовали, исследователи не уточнили.
В общем, было протестировано 18 различных языковых моделей, и сейчас партии транслируются в прямом эфире на Twitch. Их развитие как увлекает, так и дает глубокое представление о поведении ИИ в условиях сложных социальных взаимодействий.
Что это дает для развития ШИ
Эксперимент показал, что привычные бенчмарки уже не соответствуют реалиям — зато нужна проверка моделей через взаимодействие, эмоции, интриги.
«AI Diplomacy» — это:
- многомерный вызов (обман, сотрудничество, агрессия);
- понятный формат для более широкой аудитории;
- потенциал для обучения AI эмпатии и честности;
- базовая платформа, которую можно усложнять;
- пример «живой» среды для тестирования.
Вскоре планируют турниры «человек vs AI», образовательные программы, где пользователи будут учиться соревноваться с ШИ и развивать навыки коммуникации.
Предыстория реализации и потенциал будущего
По словам автора оригинальной статьи, этот проект начался после того, как исследователь искусственного интеллекта Андрей Карпатый написал в Twitter, что ему очень нравится идея использования игр для оценки больших языковых моделей по сравнению друг с другом. Ноам Браун, изучавший другой тип ШИ, способного играть в «Дипломатию», добавил: «Я с радостью посмотрел бы, как все ведущие боты играют в “Дипломатию” вместе».
Вдохновленные этой идеей, организаторы решили реализовать этот замысел. Не ради научной публикации (хотя и не исключают ее появления в будущем), а потому, что это показалось веселым и одновременно созвучным одной из долгосрочных целей. — создать игру, которая не просто развлекает, но и обучает. Идеалом была MMORPG, развивающая стратегическое мышление, коммуникативные навыки и умение договариваться — все через интерактивное взаимодействие..
В процессе организаторы не только смогли реализовать многопользовательскую среду для языковых моделей, но и выявили неожиданные черты каждого из ботов. В частности, одна из моделей — o3 — проявила ярко выраженную склонность к доминированию и манипуляциям, демонстрируя способность к обману, стратегическому планированию и хладнокровной измене.
Кроме анализа поведения искусственного интеллекта, авторы имеют и практическую цель — разработать открытую версию этой игры для более широкой аудитории. В будущем они планируют провести полноценный турнир между людьми и ШИ. Это может стать основой для появления нового жанра, где игроки взаимодействуют с языковыми моделями не как с инструментом, а как с активным противником или союзником. В то же время такая форма игры учит игроков эффективнее пользоваться ИИ в реальных ситуациях — не в теории, а на практике, в формате живой динамической игры.
Нынешний проект — не только демонстрация способностей LLM‑моделей, но и новая точка опоры для будущего ответа AI на сложные социальные вызовы. Такие игры способствуют развитию как технологий, так и гуманистического подхода к машинам, которые должны понимать не только правила, но и нас — людей.
Больше новостей читайте на GreenPost.




